뷰 - 하나 이상의 테이블을 합해 만든 가상의 테이블
테이블처럼 행과 열을 가지지만 실제로 저장하고 있지 않음
장점
편리성 및 재사용성 - 자주 사용되는 질의를 미리 정의해둠 > 간단히 작성 / 단순화해서 사용
보안성 - 사용자별로 필요한 데이터만 선별해 보여줄 수 있음 + 암호화 가능 (특정 사용자에게 필요한 필드만 보여줌)
독립성 - 미리 정의도니 뷰를 일반 테이블처럼 사용 가능 > 요구사항에 맞게 가공 > 원본 테이블에 영향x
특징
▪ 원본 데이터 값에 따라 같이 변함
▪ 독립적인 인덱스 생성이 어려움, 뷰 자신만의 인덱스를 가질 수 없음
▪ 삽입, 삭제, 갱신 연산에 많은 제약이 따름
▪ 한 번 정의된 뷰는 변경이 불가능함
기본문법
create view 뷰이름 [(열이름 [...n])]
as
select ([필드명])
from 테이블명
ex)
book 테이블에서 '축구'라는 문구가 포함된 자료만 보여주는 뷰 생성
create view vw_book as
select * from book where bookname like '%축구%';
주소에 '대한민국'을 포함하는 고객들로 구성된 뷰를 만들고 조회하시오. 뷰의 이름은 vw_Customer로 설정하시오. 4-20
create view v2_Customer as
select * from customer where address like '%대한민국%';
Orders 테이블에 고객이름과 도서이름을 바로 확인할 수 있는 뷰를 생성한 후, ‘김연아’ 고객이 구입한 도서의 주문번호,
도서이름, 주문액을 보이시오. 4-21
create view vw_orders (orderid, custid, name, bookid, bookname, saleprice, orderdate) as
select o.orderid, o.custid, c.name, o.bookid, b.bookname, o.saleprice, o.orderdate
from order o, customer c, book b
where o.custid = c.custid and o.bookid = b.bookid;
select orderid, bookname, saleprice
from vw_orders
where name = '김연아';
뷰 대체(수정) > 기존에 생성했던 뷰를 다시 새로운 뷰로 대체
create or replace view 뷰이름 [(열이름)] as select ~
4-20에서 생성한 vw_Customer는 주소가 대한민국인 고객을 보여준다.
이 뷰를 영국을 주소로 가진 고객으로 변경하시오. phone 속성은 필요 없으므로 포함시키지 마시오.
create or replace view vw_Customer (custid, name, address) as
select custid, name, address from customer where address like '%영국%';
뷰 수정 > alter
alter view 뷰이름 as
select 필드명 from 테이블명
+집계함수의 결과로 칼럼을 가진 경우 수정 불가
수정가능 여부 확인 > is_updateable = true 인 경우만
SELECT * FROM information_schema.views
where table_schema = 'madang' and table_name = 'v_customer';
뷰 삭제 > drop
drop view 뷰이름
뷰가 있어도 테이블 삭제 가능 > 테이블 삭제 시 뷰도 자동 삭제
뷰 내용 확인
describe 뷰이름;
show create view 뷰이름;
내용 추가
일부 필드만 있는 경우 (해당 필드에 not null 조건) 뷰를 통해 입력하는 것 불가능
연습문제
다음에 해당하는 뷰를 작성하시오. 데이터베이스는 마당서점 데
이터베이스를 이용한다.
(1) 판매가격이 20,000원 이상인 도서의 도서번호, 도서이름, 고객이름, 출판사, 판매가
격을 보여주는 highorders 뷰를 생성하시오.
create view highorders ( custid, bookname, name, publisher, saleprice )as
select c.custid, b.bookname, c.name, b.publisher, o.saleprice
from orders o, book b, customer c
where o.saleprice >= 20000;
(2) 생성한 뷰를 이용하여 판매된 도서의 이름과 고객의 이름을 출력하는 SQL 문을 작
성하시오.
select bookname, name
from highorders ;
(3) highorders 뷰를 변경하고자 한다. 판매가격 속성을 삭제하는 명령을 수행하시오.
삭제 후 (2)번 SQL 문을 다시 수행하시오.
alter view highorders (custid, bookname, publisher) as
select c.custid, b.bookname, c.name, b.publisher from orders o, book b, customer c;
인덱스

실제 데이터가 저장되는 곳 - 보조기억장치(하드디스크, ssd, usb 등)
엑세스 시간
탐색시간(엑세스 헤드를 트랙에 이동시키는 시간) + 회전지연 시간(섹터가 엑세스 헤더에 접근하는 시간)
+데이터 전송시간(데이터를 주기억장치로 읽어오는 시간)
> 데이터 저장 및 읽기에 많은 영향 끼침
디스크는 주기억장치보다 매우 느려 dbms가 하드디스크에 데이터를 저장하고 읽어오는데 속도 문제 발생
> 주기억장치에 dbms가 사용하는 공간 중 일부를 버퍼풀로 만들어 속도 문제 줄임
db는 버퍼에 자주 사용하는 데이터 저장 > 사용빈도가 높은 데이터 저장 및 관리
데이터 검색 시 버퍼 풀에 저장된 데이터 우선 읽고 작업 진행

인덱스(index 색인) - 데이터를 쉽고 빠르게 찾을 수 있도록 만든 자료구조 (투플 키값에 대한 물리적 위치 기록)
각 노드는 키값과 포인터 가짐
키값 오름차순 저장 (왼쪽이 키값보다 작은 값 / 오른쪽이 키값보다 큰 값을 가진 다음 노드 가리킴)
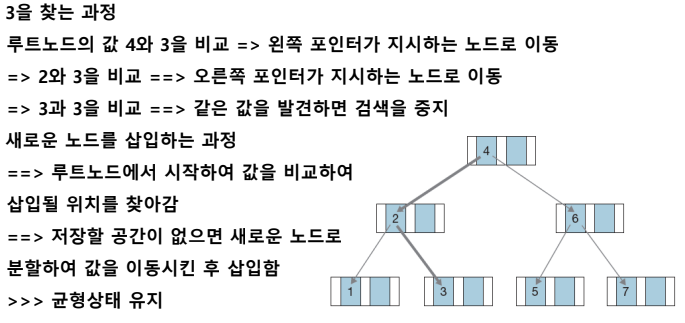
특징
▪ 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성함
▪ 빠른 검색과 함께 효율적인 레코드 접근이 가능함
▪ 순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지함
▪ 저장된 값들은 테이블의 부분집합이 됨
▪ 일반적으로 B-tree 형태의 구조를 가짐
▪ 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스의 재구성이 필요함
단점
▪ 인덱스도 공간을 차지해서 데이터베이스 안에 추가적인 공간(대략 10%)이 필요함
▪ 처음에 인덱스를 만드는데 시간이 오래 걸릴 수 있음
▪ 데이터의 변경 작업이 자주 일어나면 오히려 성능이 더 나빠질 수도 있음
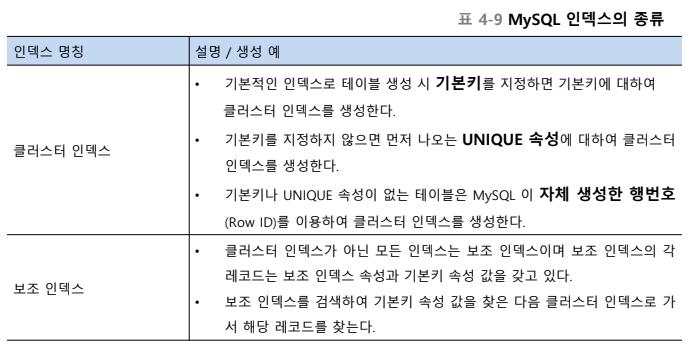
인덱스 생성 시 고려사항
▪ 인덱스는 WHERE 절에 자주 사용되는 속성이어야 함
▪ 인덱스는 조인에 자주 사용되는 속성이어야 함
▪ 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음(테이블당 4~5개 정도 권장)
▪ 속성이 가공되는 경우 사용하지 않음
▪ 속성의 선택도가 낮을 때 유리함(속성의 모든 값이 다른 경우)
기본문법
create [unique] index 인덱스명
on 테이블명 (컬럼 asc / desc) ;
show index from 테이블명;
Book 테이블의 bookname 열을 대상으로 비 클러스터 인덱스 ix_Book을 생성하라
>> create index ix_book on book (bookname);
Book 테이블의 publisher, price 열을 대상으로 인덱스 ix_Book2를 생성하시오.
>> create index ix_book2 on book (publisher, price);
인덱스 재구성(최적화) - analyze table 명령 사용
> analyze table 테이블명;
인덱스 삭제 - drop index 인덱스명 on 테이블명;
인덱스 실습
1. primary 키나, unique한 필드 없이 테이블 생성
create table usertbl
(userid varchar(8) not null ,
name varchar(10) not null,
birthYear int not null,
city varchar(5) not null);
2. 데이터 추가
insert into usertbl values ('zzz','name3',1990,'서울');
insert into usertbl values ('aaa','name2',1990,'서울');
insert into usertbl values ('ppp','name1',1990,'서울');
3. 테이블 삭제후 userid 를 unique 로 두고 테이블 재생성,
userid2 보조 인덱스 추가
create table usertbl
(userid varchar(8) unique not null ,
name varchar(10) not null,
birthYear int not null,
city varchar(5) not null);
show index from usertbl;
alter table usertbl add column userid2 varchar(8) not null unique;
4. 데이터 추가
insert into usertbl values ('zzz','name3',1990,'서울','aaa');
insert into usertbl values ('aaa','name2',1990,'서울','ccc');
insert into usertbl values ('ppp','name1',1990,'서울','bbb');
5. primary key 가 없는 경우에는 어떤 컬럼이 인덱스가 되는지 확인해보자.
drop index userid on usertbl;
-- 데이터 확인 --
create table usertbl
(userid varchar(8) unique not null ,
name varchar(10) unique not null,
birthYear int not null,
city varchar(5) not null);
alter table usertbl add column userid2 varchar(8) not null primary key;
ALTER TABLE usertbl drop primay key;
alter table customer add constraint pk_name primary key(name);
연습문제
부서를 2번 바꾼 사람의 수
create view v_emp_dept1 as
select emp_no, count(dept_no) cnt from dept_emp group by emp_no
having cnt >= 2;
select count(*) from v_emp_dept1;
부서별 연봉이 제일 큰 사람의 부서번호와 연봉
create view ds_view as
select d.dept_no, s.salary
from dept_emp d join salaries s join employees e
on d.emp_no = s.emp_no and e.emp_no = s.emp_no
where d.to_date = '9999-01-01' and s.to_date = '9999-01-01';
select dept_no, max(salary) from ds_view group by dept_no;
프로시저
create procedure로 정의
선언부와 실행부로 나뉨 ( befin ~ end)
선언부에서 변수와 매개변수 선언 > 실행부에서 프로그램 로직 구현
in 또는 out 매개변수는 저장 프로시저가 호출될 때 그 프로시저에 전달되는 값
변수는 저장 프로시저나 트리거 내에서 사용되는 값
특징
존재하지 않는 테이블을 이용해 프로그램 작성 가능 > 실행 즉 호출 전에만 존재하면 됨
테이블처럼 데이터 베이스 내부에 저장됨
보통 delimiter를 ; 로 사용하는데 sql문과 프로시저 사이 끝이 애매모호 해져 보통 다른 delimiter로 바꿔서 사용함
ex)
delimiter //
create procedure dorepeat(p1 int)
begin
set @x = 0;
repeat set @x = @x + 1; until @x > p1 end repaet;
end //
delimiter ;
call dorepeat(1000);
select @x;
프로시저로 데이터 삽입 작업 시 좀 더 복잡한 조건의 삽입 작업을 인자 값만 바꿔 수행 가능 or 호출
제어문 사용해 프로시저 작성 가능
커서 - 실행 결과 테이블을 한 번에 한 행씩 처리하기 위해 테이블의 행을 순서대로 가리키는 데 사용
>반복 구간 설정해 특정 작업을 행이 끝날때 까지 진행함
트리거
데이터의 변경 (insert, delete, update) 문이 실행될 때 자동으로 따라서 실행되는 프로시저
사용자가 추가 작업을 잊어버리는 실수 방지 > 데이터 무결성
테이블에 입력, 수정, 삭제되는 정보를 백업하는 용도로 활용 가능
종류 - defore트리거, after트리거
create table book_log (
bookid int, bookname varchar(40), publisher varchar(40), price int ) ;
delimiter //
create trigger after_insert_book
after insert on book for each row
begin
insert into book_log
values (new.bookid, new.bookname, new.publisher, new.price);
end //
delimiter ;
insert into book values(14, '스포츠 과학 1', '이상미디어', 25000);
select * from book_log where bookid='14'
'kosta_이론' 카테고리의 다른 글
| 25.04.02 트랜잭션 (0) | 2025.04.02 |
|---|---|
| 25.04.01 데이터 모델링, 정규화 (2) | 2025.04.01 |
| 25.03.28 sql 고급 (0) | 2025.03.28 |
| 25.03.27 sql + 연습문제 (1) | 2025.03.27 |
| 25.03.26 데이터베이스 (0) | 2025.03.26 |